
Prensa, robots y hemerotecas digitales: cómo las máquinas aprendieron a leer el periódico
Page content
Prensa, robots y hemerotecas digitales: cómo las máquinas aprendieron a leer el periódico
En 2021 nos propusimos escribir un artículo sobre la situación actual de la digitalización de prensa histórica: se trataba de exponer la importancia del reconocimiento óptico de caracteres (OCR) y de las tecnologías que permiten optimizarlo para facilitar el acceso a las colecciones. Cuatro años después nos encontramos con un panorama marcado por la inteligencia artificial generativa, que con nuevos modelos de lenguaje y herramientas avanzadas, a pesar de sus limitaciones y alucinaciones, abre nuevos caminos para el acceso a texto e imágenes. Se diría que las máquinas han aprendido a leer el periódico.
Caras y caretas (Buenos Aires), 13/4/1935.
La BNE escogió años antes su camino: aprovechar al máximo sus recursos para digitalizar los periódicos antes de que sucumban a la acidez del papel prensa. No apostamos por dedicarlos a mejorar de entrada el OCR –el texto que generamos a partir de la imagen–, y esto ha permitido que ya en 2025 podamos contar con el grueso de la colección de prensa histórica digitalizada. Es cierto que, especialmente la que se digitalizó en los primeros tiempos de la Hemeroteca Digital (un cuarto de siglo ya desde el inicio de los trabajos) ofrece un OCR bastante defectuoso, y esto limita la aplicación de las herramientas que los humanistas digitales emplean para analizar las colecciones.
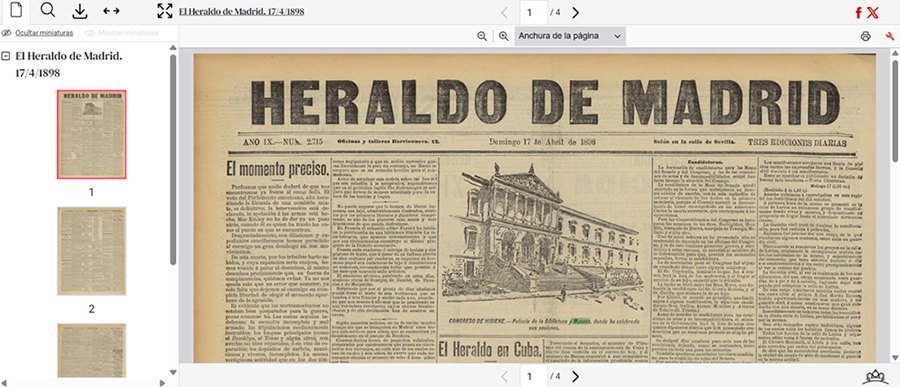
Por eso nuestra próxima obligación debería ser aprovechar las nuevas tecnologías para enriquecer estos contenidos y generar una representación textual exacta, que permita hacer búsquedas precisas, así como extraer los textos estructurados para procesarlos, almacenarlos y someterlos a las tareas de análisis automático que requieren los investigadores.
En el caso de los periódicos resultaría imprescindible recurrir a técnicas de reconocimiento óptico de la composición (OLR: Optical Layout Recognition), que permiten separar las distintas áreas en que se distribuyen el texto y las imágenes sobre la página, e incluso identificar correctamente cada artículo y cada bloque textual, caracterizar cada parte del diario (columnas, novelas por entregas, anuncios, esquelas, tablas) y, conforme avanza la técnica, llegar a la aplicación de tecnologías de visión artificial para identificar las imágenes según su naturaleza (fotografías, ilustraciones, tiras cómicas) e incluso analizar su contenido, a fin de ampliar a ellas las funciones de clasificación y búsqueda que ofrece la interfaz de usuario.
Ya en 2021 veíamos en el mundo una amplia muestra de proyectos en torno a colecciones de periódicos enriquecidas y estructuradas, con aplicaciones que a veces sonaban a ciencia ficción.
En realidad, se empezó años antes. Por ejemplo, tenemos el proyecto IMPACT: Improving Access to Text (2008-2011), en el que colaboraron la Biblioteca Nacional de España, la Universidad de Alicante y la Biblioteca Virtual Miguel de Cervantes. Impulsado por la Unión Europea, IMPACT se puso en marcha con el fin de mejorar el acceso a los textos históricos y superar las barreras que obstaculizaban la digitalización masiva del patrimonio cultural europeo. Este proyecto continuó desde 2012 con el Impact Centre of Competence in Digitisation, organización sin ánimo de lucro participada por instituciones públicas y privadas, con la misión de hacer la digitalización de textos impresos históricos “mejor, más rápida y más barata”.
Y, en paralelo, desde la desaparecida The European Library (TEL) se impulsó el proyecto Europeana Newspapers (2012-2015), que continuó con la migración de sus contenidos y funciones al marco de la biblioteca digital Europeana, en cuyo ámbito se difundieron iniciativas que aportaron contenidos todavía relevantes, como vemos en la 16ª entrega de Europeana Tech Insight (2020), el boletín que elaboraba su comunidad de expertos, desarrolladores e investigadores.
Posteriormente encontramos diversos proyectos de carácter estatal, como el francés Retronews, basado en un modelo de suscripciones, o el portal de prensa histórica de la Biblioteca Digital Alemana: Deutsches Zeitungsportal.
En torno a estas colecciones se han desarrollado herramientas relacionadas con la identificación de artículos, optimización del OCR y aplicación de técnicas de NER (Named Entities Recognition o Reconocimiento de Entidades Nombradas, que permite a la máquina reconocer que quien está detrás de la palabra “Cervantes”, impresa en un artículo del periódico, es el mismo don Miguel) para la identificación automática y el enlazado de nombres de entidades (personas, materias, obras, entidades corporativas y lugares) con servicios en línea y ficheros de autoridades, así como la aplicación de técnicas optimizadas de OCR y OLR, con herramientas de machine learning e inteligencia artificial que permiten identificar los titulares y las áreas de texto e imágenes, así como el orden de lectura de los distintos bloques textuales.
En relación con esta iniciativa, también tuvieron importancia proyectos como los siguientes:
- OCR-D: busca aportar un marco técnico y organizativo para el proceso OCR de las colecciones digitalizadas de textos históricos alemanes, en un proceso de desarrollo abierto y transparente que difunde tanto especificaciones y guías técnicas como herramientas de acceso abierto.
- Qurator: proyecto del gobierno alemán con la participación de entidades dedicadas al desarrollo de tecnologías de IA, machine learning y tecnologías del lenguaje, para el desarrollo de herramientas de proceso y conservación de contenidos digitales.
- SoNAR (IDH): centrado en la visualización de datos y en el desarrollo de interfaces de consulta gráficos, como herramientas de análisis de las relaciones entre nombres de personas y entidades extraídos de textos como periódicos digitalizados.
En el campo específico de la aplicación de técnicas de visión artificial para el reconocimiento de imágenes destaca el trabajo de KB Lab, el sitio web de la Biblioteca Nacional de los Países Bajos que recoge los conjuntos de datos y las herramientas experimentales desarrollados a partir de sus colecciones digitales. En el caso de las colecciones de periódicos, albergadas en el portal Delpher, encontramos conjuntos de datos obtenidos con el fin de clasificar las imágenes extraídas de los periódicos digitalizados y realizar búsquedas en función de distintos parámetros visuales y textuales.

En los Estados Unidos, el referente en materia de digitalización de prensa histórica es Chronicling America, el repositorio mantenido por el National Digital Newspaper Program. A partir de este se puso en marcha en 2019 el proyecto Newspaper Navigator, centrado en la aplicación de técnicas de machine learning a sus contenidos.
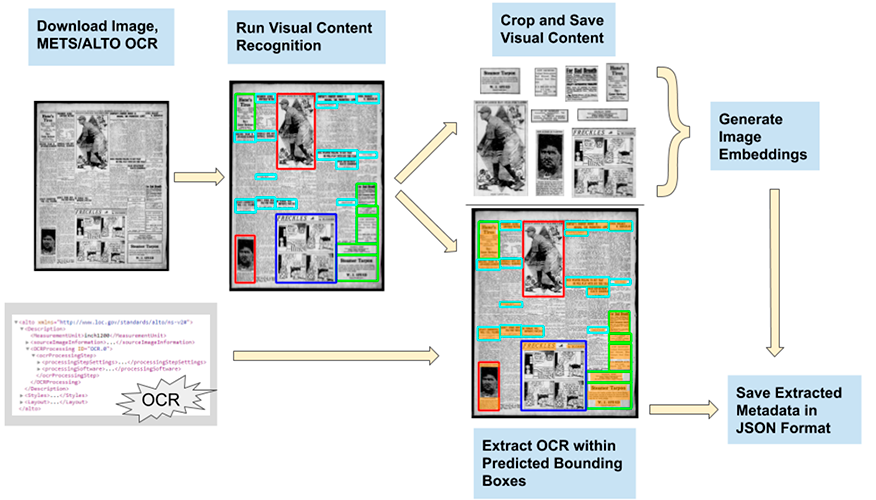
Comprendió dos fases: la extracción de contenido visual (fotografías, ilustraciones, viñetas, tiras cómicas, mapas, titulares y anuncios) de sus millones de páginas, y el desarrollo de una interfaz de búsqueda y exploración que permitiera al usuario navegar por todo ese material gráfico. Como resultado de la primera fase se publicó en abril de 2020 el Newspaper Navigator dataset, y la segunda se concretó en septiembre de 2020 con la publicación de la Newspaper Navigator search application.
El modelo de aprendizaje automático que permitió generar este conjunto de datos se basó en los resultados de Beyond Words, un proyecto colaborativo en el que los usuarios de la colección ayudaron a identificar algunas imágenes seleccionadas. A estos datos se sumó la aplicación de técnicas avanzadas de reconocimiento visual y el uso de redes neuronales, así como la inclusión como metadatos textuales del OCR incluido en estas imágenes.
La prensa digitalizada ha resultado ser un campo interesante para los investigadores en inteligencia artificial, lo que ha llevado a iniciativas como la Shared Task HIPE “Identifying Historical People, Places and other Entities”, campaña para la evaluación del proceso de entidades nombradas (NER) y enlazado (Named Entity Linking) en periódicos históricos franceses, alemanes e ingleses, organizada en el contexto del proyecto Impresso.
Impresso – Media Monitoring of the Past es un proyecto suizo centrado en facilitar el acceso al texto completo de grandes colecciones de periódicos, para lo que desarrolló una novedosa interfaz de usuario que permite buscar, procesar, enlazar y explorar los datos extraídos de estas colecciones. Se trata de una iniciativa interdisciplinar en la que un equipo de lingüistas computacionales, diseñadores e historiadores colaboran en la indexación semántica de un corpus multilingüe de periódicos digitalizados de Suiza y Luxemburgo.
Otro proyecto internacional destacado fue Oceanic Exchanges: Tracing Global Information Networks in Historical Newspaper Repositories, 1840-1914. Se centró en el estudio de redes globales y del flujo de patrones de información a través de fronteras nacionales y lingüísticas, mediante el análisis computacional de repositorios de prensa histórica digitalizada. Resultado de este proyecto colaborativo es la publicación del Atlas of Digitised Newspapers and Metadata, que reúne la descripción detallada de diez grandes repositorios de todo el mundo, como la Hemeroteca Digital Nacional de México.

La Unión Europea también participo en este campo a través del proyecto News Eye, incluido en el programa de investigación e innovación Horizonte 2020. Además de permitir el acceso en línea a los documentos, con las conocidas facilidades para realizar búsquedas textuales, la digitalización permite llevar a cabo operaciones de análisis automatizado que no habrían sido posibles en la biblioteca tradicional, en particular en el caso de los periódicos digitalizados: análisis de redes, de patrones y tendencias, de discurso, topic modelling (detección de la repetición de combinaciones de palabras dentro de un artículo para establecer la probable temática del mismo), data mining, análisis cuantitativos, identificación de patrones lingüísticos, estudio de fenómenos distribuidos geográficamente y, en definitiva, cualquier aproximación que haga uso de herramientas digitales sobre el caudal de información representada en los documentos digitalizados.

News Eye reunió diversas de estas iniciativas basadas en el tratamiento de los periódicos digitalizados, desde el proceso del OCR para obtener textos de calidad hasta la aplicación de NER, clasificación automática o NLP (Natural Language Processing o Procesamiento del Lenguaje Natural). Estas herramientas permitirían enriquecer los datos bibliográficos de los periódicos facilitando la separación de artículos y el reconocimiento de texto completo a nivel de artículo, así como llevar a cabo un análisis semántico avanzado del texto y el desarrollo de métodos para encontrar automáticamente temas, tendencias, puntos de vista, etc.
Y estos son solo algunos de los proyectos que encontrábamos ya en 2021, y que están en la base de las iniciativas que han continuado hasta el día de hoy. Un día marcado por la explosión de la IA generativa, que más allá del hype ha venido a cambiar el panorama, o al menos a ampliar el campo de batalla. Otro día hablaremos de las hemerotecas digitales –más allá de la nuestra–, de la digitalización del patrimonio hemerográfico como proyecto necesariamente colaborativo y de todas las fuentes que han enriquecido el terreno en el que se mueve el humanista digital.
El caso es que todos estos avances tecnológicos suponen un importante desafío para las bibliotecas que mantienen colecciones de periódicos digitalizados, y que deberán atender la demanda de un público que requerirá la máxima precisión en la calidad de los textos y un acceso individualizado a los artículos e imágenes de los diarios. Para ello será especialmente valiosa tu colaboración, diligente humanista digital que has llegado hasta aquí, y que por tanto entiendes las posibilidades que abre la combinación de la máquina con estas bibliotecas que cada día amplían la digitalización de nuestro patrimonio cultural. ¿Conoces otros proyectos construidos sobre la digitalización de la prensa histórica? ¿Sabes qué ha sido de estos y qué panorama encuentra la comunidad investigadora en la actualidad? ¿Qué nuevas puertas han abierto la IA y la tecnología de última generación? ¿Qué necesitas de las bibliotecas y qué más puedes aportar a esta comunidad?
Como conclusión, vemos que los avances técnicos despejan infinidad de nuevos caminos en el proceso de las imágenes digitalizadas, y los mecanismos de inteligencia y visión artificial, así como el análisis textual o el reconocimiento de entidades, prometen aproximaciones insospechadas al análisis informático de la prensa histórica y el desarrollo de herramientas asombrosas. En definitiva, plantean nuevas y enormes exigencias a las instituciones y al mundo académico, tanto para completar la necesaria digitalización de las colecciones históricas (incluidas las revistas, también amenazadas por un proceso de degradación material irreversible), como para optimizar la calidad de las imágenes y los textos digitalizados: esta debería ser nuestra próxima tarea.
Algunas referencias
Europeana Tech Insight. Issue 16: Newspapers (2020, october)
Europeana Tech Insight. Issue 13: OCR (2019, july)
Lonij, J., Wevers, M. (2017) SIAMESE. KB Lab: The Hague.
Smits, T., Faber, W.J. (2018) CHRONReader. KB Lab: TheHague.
Smits, T., Faber, W.J. (2018) CHRONIC (Classified Historical Newspaper Images). KB Lab: The Hague.
Algunas colecciones destacadas de prensa histórica
Biblioteca Nacional de Finlandia
Chronicling America (Library of Congress, Estados Unidos)
Delpher (Países Bajos)
E-newspaperarchives.ch (Suiza)
eLuxemburgensia (Biblioteca Nacional de Luxemburgo)
Hemeroteca Nacional Digital de México
Papers Past (Biblioteca Nacional de Nueva Zelanda)
Retronews (Francia)
Trove (Biblioteca Nacional de Australia)
Recursos de prensa en el blog de la BNE
Escrito por:
Multimedia