
Transformando y enriqueciendo nuestros datos con OpenRefine
Page content
Transformando y enriqueciendo nuestros datos con OpenRefine
Hemos estado probando la herramienta OpenRefine para explorar, transformar, corregir, enriquecer… los datos de nuestro catálogo, y algunas de las pruebas son sorprendentes. ¿Quieres saber más? Te lo contamos en este post.
Primero, un poco de contexto
Desde 2015, la Biblioteca Nacional de España tiene entre sus líneas estratégicas el impulso de la reutilización de sus datos y contenidos digitales, principalmente a través del proyecto BNElab.
En este contexto, la BNE ya ha trabajado mucho en adaptar y enriquecer con tecnología semántica los datos de su catálogo a través de datos.bne.es. Con esta iniciativa, la Biblioteca se suma al reto de publicar los catálogos bibliográficos y de autoridades en formato RDF (Resource Description Framework), conforme a los principios de los Datos Enlazados (Linked Data), ambos componentes básicos de la Web Semántica.
Además, desde 2017 la Biblioteca ha abordado la tarea de apertura de sus datos, tanto bibliográficos como no bibliográficos, para favorecer e impulsar y su posterior reutilización en ámbitos tan diversos como las Humanidades Digitales y el Procesamiento de Lenguaje Natural (PLN), el turismo, big data etc. Como producto de estos trabajos, se han hecho disponibles en los últimos meses una serie de conjuntos o sets de datos, que incluyen desde los ya mencionados catálogos hasta el Archivo de la web española, pasando, por ejemplo, por las estadísticas de nuestros principales servicios.
En concreto, la publicación de nuestros datos bibliográficos ha supuesto un trabajo previo de preparación que permitiera la conversión de los mismos a formatos útiles para un público mucho más allá del bibliotecario (CSV, JSON, ODS, TXT, XML). Para ello se hizo una selección de los campos MARC que incluyen información relevante y se les asoció un literal amigable, creando un mapeo para cada uno de los conjuntos que ofrecemos desde la BNE, y que están disponibles al descargar cualquier conjunto de datos bibliográficos en nuestro portal BNElab.
Como casi siempre que se emprende una labor así, se han producido consecuencias inesperadas. En este caso, nos hemos dado cuenta de que estos conjuntos de datos pueden ser muy útiles no solo de cara al exterior, sino también para nuestros propios trabajos de proceso técnico. Un catálogo de las dimensiones del nuestro no es fácilmente manejable, y la revisión y depuración de errores es una actividad incorporada desde hace tiempo a las tareas de proceso técnico en la BNE. Hasta ahora se han utilizado herramientas como Marc Report para detectar y depurar errores de formato, pero en los últimos años han surgido herramientas muy potentes que permiten un paso más allá para el análisis y tratamiento de los propios datos. Con estos nuevos formatos, y con las herramientas adecuadas, vemos que podemos revisar, analizar, corregir, hacer transformaciones masivas, cruzar con fuentes externas y enriquecer datos de nuestros catálogos de una forma mucho más sencilla y ágil que antes.
Pero entremos en harina… ¿Cómo estamos utilizando la herramienta OpenRefine? Se trata de un software de código abierto utilizado para la limpieza y transformación de datos.
Con un ejemplo se entenderá más fácilmente
Partimos del conjunto de autoridades de persona de nuestro catálogo de autoridades (1.349.798 registros). Nuestro objetivo será evaluar el estado de los registros, subsanar errores y posteriormente tratar de enriquecer el conjunto con datos adicionales.
Para este ejemplo, imaginemos que queremos estudiar el campo “género” (campo 375 $a), ya que al tratarse de un campo normalizado (masculino/femenino) debería ser fácil detectar los errores. Además, este campo no se ha rellenado de forma sistemática a lo largo de los años.
Los pasos realizados han sido:
En primer lugar, hemos realizado una “faceta de texto” sobre nuestro conjunto para comprobar los diferentes valores que presenta este campo y sorprendentemente hemos encontrando 31 opciones.
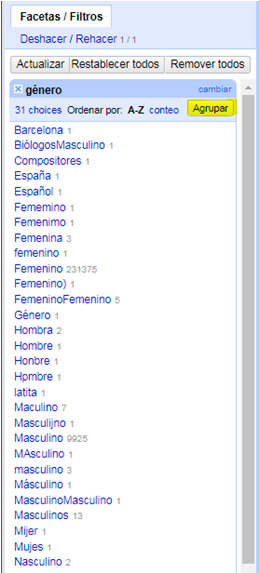
A continuación, en lugar de corregir registro a registro, OpenRefine nos ofrece una serie de algoritmos de agrupación que nos pueden ayudar a unificar valores (Key Collision Methods o Métodos de colisión clave y Métodos de vecino más cercano).
Lo ideal es utilizar, en diversas iteraciones, cada uno de los algoritmos propuestos hasta agrupar el mayor número de valores posibles. De este modo, hemos logrado reducir el número de opciones a 11.
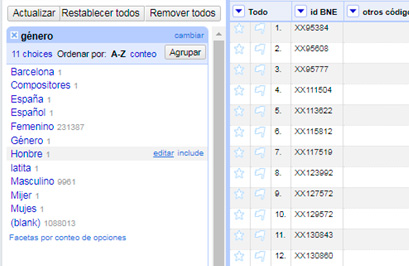
Llegados a este punto, continuar la limpieza supondrá un trabajo manual de depuración, que no se puede soslayar.
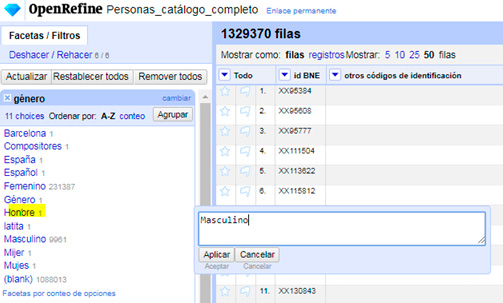
Después de esta limpieza manual llegaríamos al objetivo de distinguir masculino, femenino y blanco (esto significa que el registro no ha sido rellenado con el campo de género, como adelantábamos al principio).
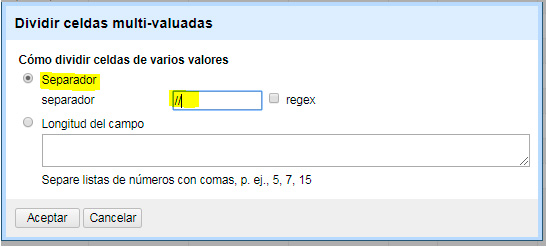
Si pensamos en otros campos MARC que nos interese estudiar, veremos que algunos son repetibles, por ejemplo, la ocupación (campo 374 $a). En estos casos encontraremos varios valores en cada celda. OpenRefine resuelve esta situación al permitir dividir celdas multi-valor y trabajarlas de forma individual, para posteriormente volver a unirlas y mantener la entidad de cada registro.
Un paso más allá: el enriquecimiento de registros
Como habéis podido ver, muchos de nuestros registros de autoridad de persona carecen de información relevante como el género, la ocupación o las fechas clave. OpenRefine nos ofrece una forma sencilla de obtener e incorporar este tipo de información a nuestros registros. Para ello se vale de los denominados “Servicios de reconciliación”.
Por una parte, existen unos servicios preestablecidos, de fuentes oficiales como Wikidata o VIAF, pero por otra parte también nos permite crear nuestros propios servicios de reconciliación con fuentes de nuestra elección; el requisito principal es que se presenten en un fichero csv.
Siguiendo con los ejemplos, imaginemos que tenemos el conjunto de datos de autores españoles fallecidos en 1938 (175 registros) y que queremos completar su género en nuestro catálogo. Podríamos utilizar el nombre de cada persona en nuestro catálogo para intentar cruzarlo con el campo análogo de su registro en Wikidata y posteriormente extraer su información para enriquecer nuestro conjunto.
Esto se realizaría en OpenRefine utilizando la opción “cotejar”. En nuestro ejemplo hemos conseguido vincular 63 registros.
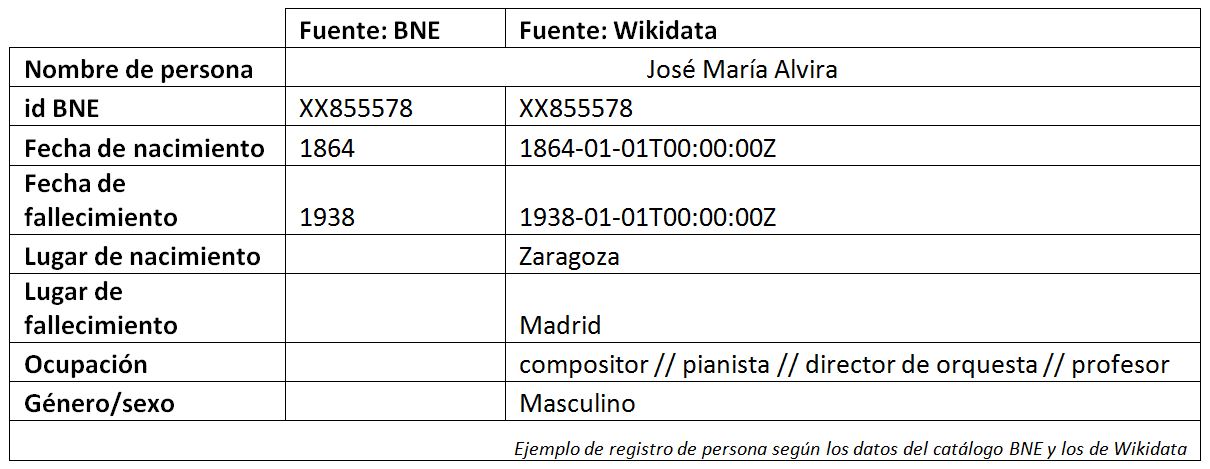
Además de estos repositorios estándar, como hemos dicho antes, podemos usar nuestros propios ficheros en formato csv como repositorios. Ilustraremos esta opción con dos ejemplos.
¿Y si en lugar de intentar cotejar contra todo Wikidata, acotamos sobre un conjunto que cumpla unas condiciones concretas? En el ejemplo de autores fallecidos en 1938 podemos hacer una consulta SPARQL a Wikidata como la siguiente:
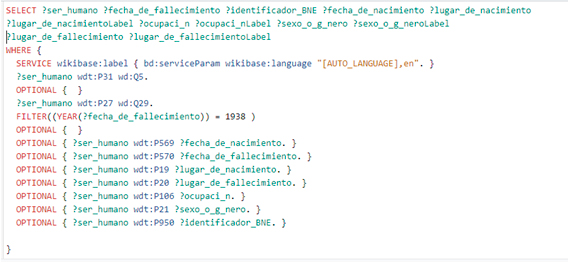
Obtenemos un fichero csv con 442 registros de persona que sabemos a ciencia cierta que fallecieron en 1938, con la información relevante que hemos seleccionado: fecha de nacimiento y fallecimiento, lugar de nacimiento y fallecimiento, ocupación, género e identificador BNE (que es nuestro número de control, campo MARC 001). Cargamos este fichero como fuente externa de reconciliación, y así mejoramos las probabilidades de acierto a la hora de cotejar con nuestro conjunto de trabajo.
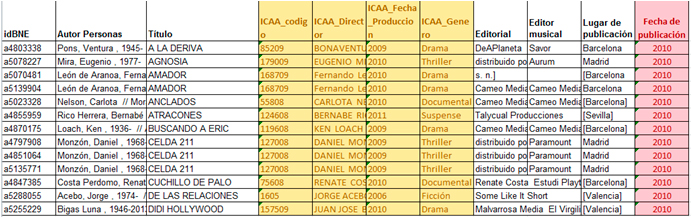
Para el segundo ejemplo, hemos querido utilizar como fuente externa un conjunto de datos de otro organismo público, el Instituto de las Ciencias y las Artes Audiovisuales (ICAA). Concretamente, vamos a utilizar su base de datos de películas calificadas, valiéndonos de su servicio web. Hemos recuperado toda su base de datos y creado un csv que, gracias a la herramienta “Reconcile-csv”, podemos convertir en nuestro repositorio de reconciliación.
Por nuestra parte, estudiaremos un subconjunto de videograbaciones de nuestro catálogo bibliográfico (concretamente, películas con fecha de publicación posterior al 2010, 3.308 registros) y nos preguntamos cuántas son españolas, puesto que esta información no está registrada en ningún campo MARC en la actualidad.
Tras cotejar los dos conjuntos a través del campo título, los resultados de coincidencia son 70 registros, al 70% de fiabilidad. Sobre estas películas coincidentes, sabemos, en principio, que son españolas, y podremos importar además los datos asociados que nos interesen, como el nombre del director o la fecha de producción.
Pero… ¿para qué sirve todo esto?
Como resultado evidente, mejoramos nuestra capacidad de evaluar nuestros catálogos de forma mucho más ágil que hasta ahora. Además, una vez evaluados, podemos corregir errores e introducir nuevos datos de forma semiautomática y por lotes, sin necesidad de que un catalogador dedique miles de horas a revisar registro a registro. Una vez generado un fichero csv con todos los datos enriquecidos y limpios, podremos exportarlo desde el OpenRefine y posteriormente importarlo en nuestro Sistema Integrado de Gestión Bibliotecaria en una única operación.
¿Qué os parece? Prueba, juega, atrévete y cuéntanoslo.
Para saber más…
Dado que no existe demasiada documentación sobre el uso de OpenRefine en español, hemos documentado nuestra experiencia en un manual de uso interno (pdf) con el que puedes conocer el software más a fondo y probarlo con tus propios datos. No dudes en contactarnos con dudas o sugerencias en nuestro buzón BNElab.
Laura Donadeo Navalón Zaira Flores Valenzuela
Multimedia
Qué interesante y cuántas nuevas posibilidades.